Data Camping
Syllabus
Motivation
This camping got inspiration from Open-Sources-Software, DataTalkClub, DataEngineeringThing, MLOps, DePodcast, etc which community for building up engineering, especially for creating Better Engineering and Building Fundamental Knowledge for Engineer
I preferred and added more expectations for the camping, you will stay in the DEH - Data Engineering Handbook and create your own works.
All the materials of the course are freely available, so that you can take the course at your own and start the project as your convince, but please make you will keep track the timeline.
Syllabus
Week 1: Introduction and Prerequisites
- Introduction to AWS, IaC
- Docker and docker-compose
- Running Postgres locally with Docker
- Setting up Snowflake Cloud Data Warehouse
- Setting up infrastructure on AWS (LocalStack) with Terraform
- Preparing the environment for the course
- Homework
- Fetching data from Internet using API/web scraping, create python function and 3 DDL for 3 normal form tables.
- Forward and Backward data format
- Setup Docker
- Practice with Snowflake
- Hosting Local AWS using Terraform
Week 2: Data Ingestion
- Workflow orchestration
- Setting up Airflow locally
- Ingesting data to AWS with Airflow
- Ingesting data to local Postgres with Airflow
- Moving data, migrating data
- Homework
- Setup Python data pipeline with Airflow
- Sample End-to-End data pipeline
- Collect data from API, Database
- Practice Schedule job, Change data Capture
Week 3: Data Warehouse
- Data Warehouse
- Data Sourcing System
- Distributed System
- Iceberg / Snowflake
- Partitioning and Clustering
- Best practices
- Snowflake works
- Integrating Snowflake with Airflow
- Iceberg / Snowflake Machine Learning - Advanced
- Homework“ “- Setup data Warehouse on Snowflake
- Setup MinIO for datalake
- Build Pipeline to load data from datalake to data warehouse with idempotent pattern
Week 4: Analytics Engineering
- Basics of analytics engineering
- dbt (data build tool)
- Iceberg and dbt
- Postgres and dbt
- dbt models
- Testing and documenting
- Deployment to the cloud and locally
- Visualizing the data with google data studio and metabase (preferred)
- Transform data with Dbt
- Schedule dbt pipeline with Airlfow (Astronomer)
- Connect BI tool (Google Studio / Metabase) with data warehouse and create dashboard“
Week 5: Batch Processing
- Batch processing
- What is Spark
- Spark Dataframes
- Spark SQL
- Internals: GroupBy and joins
- Processing large data with Spark
- Trigger and schedule spark job
- Apply Spark job to process ML pipeline
Week 6: Streaming Processing
- Introduction to Kafka
- Schemas (avro)
- Kafka Streams
- Kafka Connect and KSQL
- Process streaming data with Kafka
- Setup schema register and validation
- Analyze real-time data
- Process late data with kafka
Week 7: Data Quality
- Six data quality dimensions
- Data validation with Great Expectations and Deequ
- Anomaly detection and incremental validation with Deequ
- DataHub for data governance
- Implement data quality and data profiling (schedule quality gate)
- Implement dataops with dbt and scheduling with Airflow
- Data Quality with Great Expectations
- Research data governance tool, understand governance and management data system“
Week 8: Orchestration and Automation
- Pipeline orchestration benefits
- Creating Data Lineage
- Event-based vs time-based ; business driven vs data driven
- Research data lineage
- Design data model for logging and lineage
Week 9 : Capstone Project
- Week 9: working on your project
- Week 10 (extra): reviewing your peers
- To be defined with real project
Architecture diagram
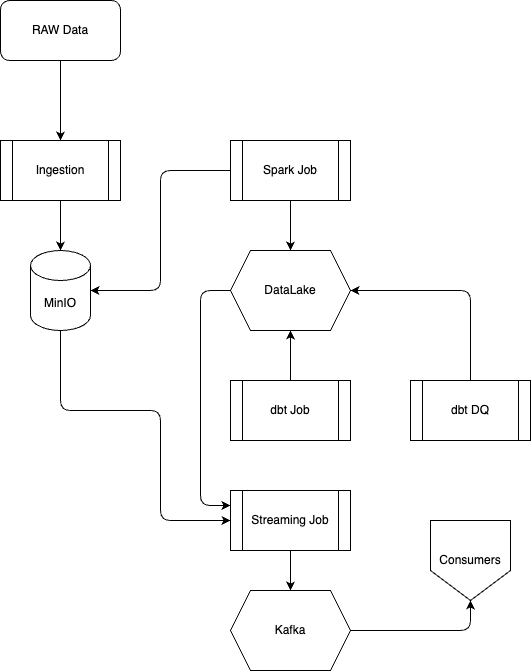
Technologies
- Amazon Web Service (AWS): Cloud-based auto-scaling platform by Amazon
- Amazon Simple Storage (S3): Data Lake
- Redshift: Data Warehouse
- Terraform: Infrastructure-as-Code (IaC)
- Docker: Containerization
- SQL: Data Analysis & Exploration
- Airflow: Pipeline Orchestration
- dbt: Data Transformation
- Spark: Distributed Processing
- Kafka: Streaming
(Alternative - No Cost solution):
- Iceberg: Open-source data warehouse or Clickhouse
- Snowflake: High-class data warehouse on Cloud
- MinIO: Data Lake - compatible with S3
Prerequisites
- Proficiency in Python and SQL, at least 3 months of experience in both
- Basic understanding of Docker, Kafka, and Spark is PLUS
Tools
Follow the dotfile