AWS Overview for Data Engineering Projects
Introduction
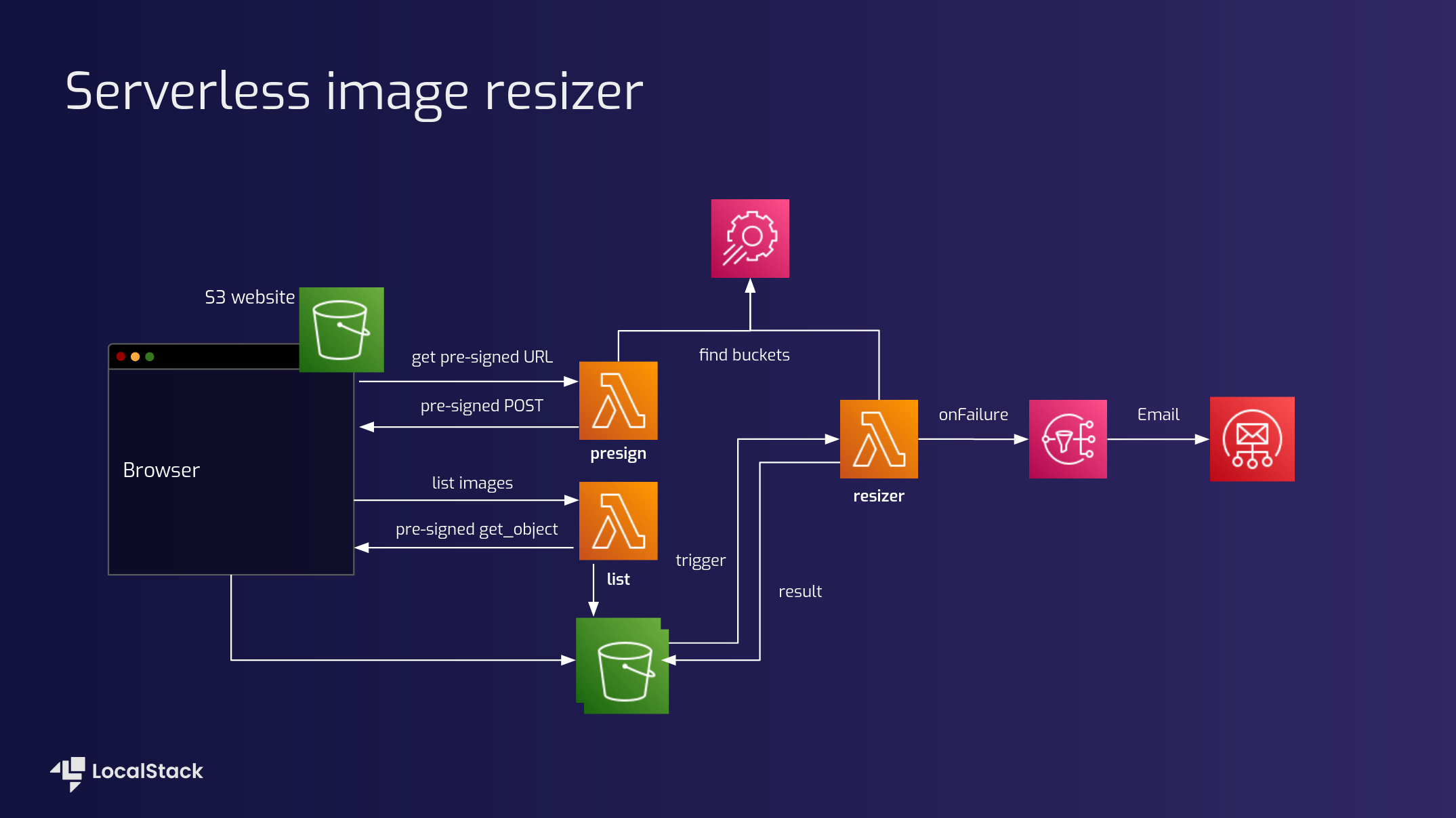
Amazon Web Services (AWS) offers a wide range of cloud services that are highly valuable for data engineering projects. These services provide scalable, reliable, and cost-effective solutions for storing, processing, and analyzing large volumes of data.
Key AWS Services for Data Engineering
Watch this as Sample AWS Project
-
Amazon S3 (Simple Storage Service): S3 is a highly scalable object storage service that allows you to store and retrieve any amount of data. It is commonly used as a data lake for storing raw data before processing.
-
Amazon Redshift: Redshift is a fully managed data warehousing service that allows you to analyze large datasets using SQL queries. It is optimized for online analytical processing (OLAP) and is commonly used for data warehousing and business intelligence.
-
Amazon Glue: Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It provides a serverless environment for running ETL jobs and supports various data sources and formats.
-
Amazon EMR (Elastic MapReduce): EMR is a managed big data platform that simplifies the processing of large datasets using popular frameworks like Apache Spark, Hadoop, and Presto. It provides scalable compute resources and supports various data processing tasks.
-
Amazon Athena: Athena is an interactive query service that allows you to analyze data directly from S3 using standard SQL queries. It eliminates the need for data loading or ETL processes and provides quick insights into your data.
-
Amazon Kinesis: Kinesis is a real-time streaming data platform that allows you to ingest, process, and analyze streaming data at scale. It is commonly used for real-time analytics, log processing, and IoT data processing.
Additional Resources
This is just a brief overview of some key AWS services used in data engineering projects. For more detailed information and best practices, refer to the provided resources.
Local Development with LocalStack
When developing AWS applications locally, it can be beneficial to use a tool called LocalStack. LocalStack is a fully functional local AWS cloud stack that allows you to emulate various AWS services on your development machine.
With LocalStack, you can create and test your AWS infrastructure locally without incurring any costs or making actual API calls to AWS. It provides a convenient way to develop and debug your applications before deploying them to the actual AWS environment.
To use LocalStack for local development, you can follow these steps:
-
Install LocalStack: Start by installing LocalStack on your development machine. You can find installation instructions in the LocalStack GitHub repository.
-
Configure LocalStack: Once installed, you need to configure LocalStack to emulate the AWS services you require for your development. This can be done through a configuration file or environment variables.
-
Start LocalStack: Start the LocalStack service on your machine. This will spin up a local environment that emulates the selected AWS services.
-
Develop and Test: With LocalStack running, you can now develop and test your AWS applications locally. You can make API calls to the emulated AWS services just like you would with the actual AWS services.
-
Cleanup: After you are done with your local development and testing, make sure to clean up any resources created by LocalStack to avoid any conflicts or resource leaks.
LocalStack is a powerful tool that can greatly enhance your local development workflow when working with AWS services. It allows you to iterate quickly and efficiently without the need for a live AWS environment.
For more information and detailed usage instructions, refer to the LocalStack documentation.
Start the LocalStack
docker-compose up -d
docker-compose down
docker-compose stop