Week 3 - Data Warehouse
What this video https://youtu.be/8Lfoe_iYUAk?si=QKphrQfs8Dm6y6IU
“If you can not download file,”
I put the sample code here: Github repository
Data Architecture
- Normalize and denormalize (Normal-Form)
- Data Modeling: Relational Model –> Dimensional Model –> Super table –> Delta table
- Data architectures: Data Fabric (agile platform, framework for management) and Data Mesh (decentralized architecture, domain focused, 360 data), Data Vault (enterprise, data-linkage)
- Data management systems: Data Warehouse, Data Mart, Data Lake and LakeHouses
- Data processing architectures: Lambda, Kappa and DataFlow
Storage Pattern
- Data Storage Systems: File Storage, Object Storage, Block Storage, Cache, HDFS and Streaming Storage
- ACID, Idempotent, Atomic
- Table Partitioning, Clustering
- Data Lake table formats: Delta Lake, Iceberg and Hudi
- Advanced Schema Design, Best Practices - Video
Data Extracting, and Loading
We have already mentioned that in this handbook, answer to the following questions:
- How to extract the data from raw data? (regex pattern, etc)
- How to extract the delta data from sources (delta data is the subset of data changed) ?
- Do we need a buffer for loading?
- etc…
Depending on the data source and data availability requirements, the data will be loaded and refreshed as needed.
When dealing with Source data ingestion, type of data loads is determined by:
- Full Load: loading small data (ex: dimensions, master data, etc)
- Delta Load: transactional data (delta extraction by using incremental columns)
Another, you’re working to load data to Target data loading, try to use these engineering technique to load data:
- Incremental: split data into smaller chunks
- Snapshot: snapshot data and merge into destination
“Key words for loading data from sources and targets”
Plus: Engineering columns during data loading and data transformation ?
From Source: source of data was fromIncremental Columns: seq, auto_increment(col), modified column,created columnHistorical Tracking Columns: version, modified_datetime, created_datetimeDescriptive Columns: Dimension columns, natural key(col)Identifier Column: mostly PK and FKAudit Column: Record_ID for backfilling data, data mismatch,
Distributed System
Key Focus for Distributed Systems
-
Understanding distributed computing principles and concepts
-
Familiarity with distributed system architectures (e.g., client-server, peer-to-peer)
-
Proficiency in distributed data management and synchronization techniques
-
Experience with distributed system scalability and fault tolerance strategies
-
Understanding of distributed system security and data privacy considerations
-
Proficient in designing and implementing distributed system workflows and pipelines
-
Familiarity with distributed system monitoring and performance optimization techniques
Data Warehouse and Snowflake
Starting this Snowflake 101
Micro-partition and Data Clustering
- In Snowflake, the concept of physical partitions (like in traditional databases) does not exist because Snowflake automatically divides the data into micro-partitions behind the scenes.
Groups of rows in tables are mapped into individual micro-partitions, organized in a columnar fashion
- Clustering information is in order to avoid unnecessary scanning of micro-partitions during querying
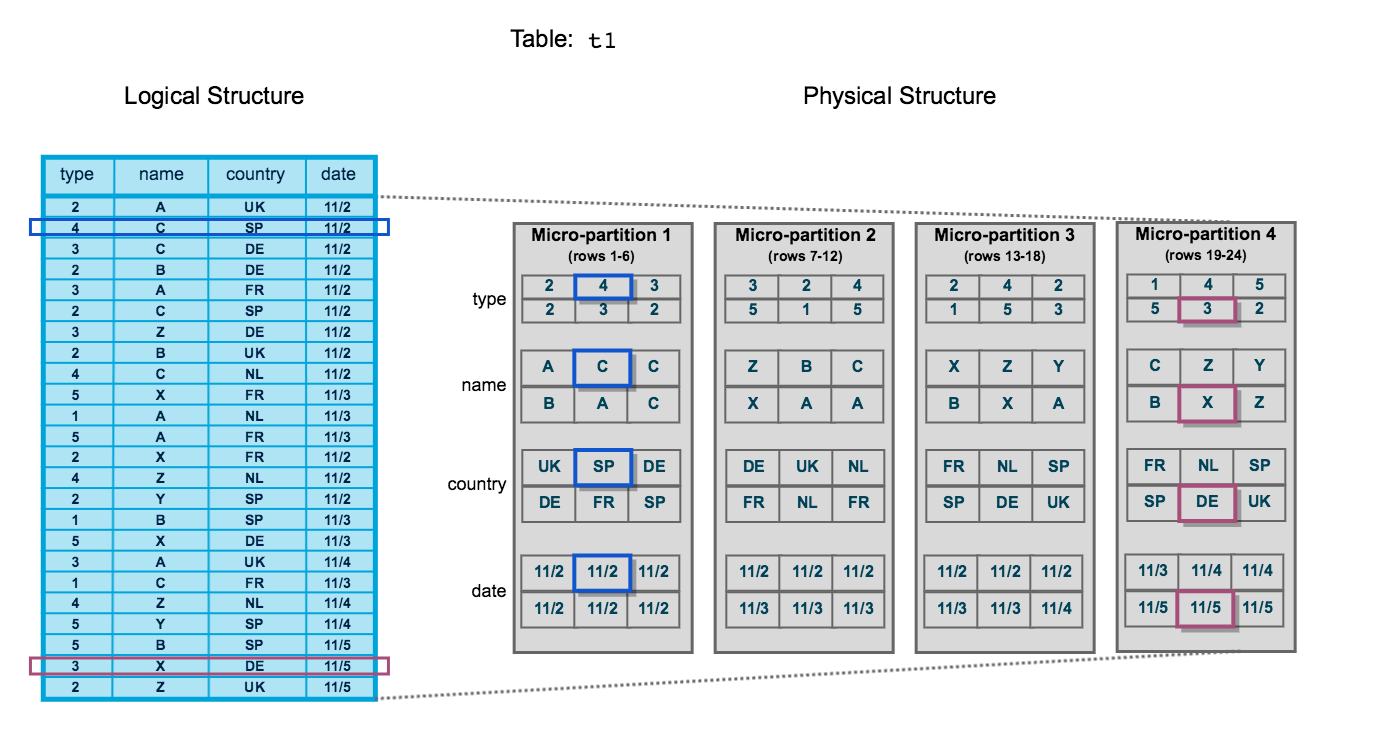
-
The table consists of 24 rows stored across 4 micro-partitions, with the rows divided equally between each micro-partition. Within each micro-partition, the data is sorted and stored by column, which enables Snowflake to perform the following actions for queries on the table:
- First, prune micro-partitions that are not needed for the query.
- Then, prune by column within the remaining micro-partitions.
Do not put the unnecessary column into the query if you do not really need these columns appear.
Partitioning and Clustering (Distribution)
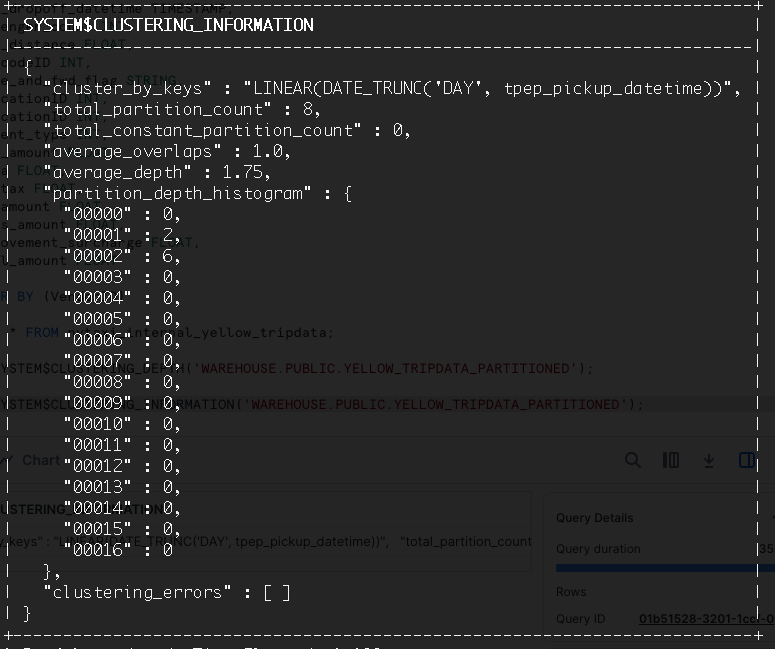
If you are not using the Snowflake
- Partition table will be involved
- A lot of Open Sources are available for community, startup: ClickHouse, Doris, ect
- But from Snowflake, you may have known about why Snowflake helps us to resolve the partition management and focus on data analytics purposes and data consuming
9 rows in set. Elapsed: 0.061 sec. Processed 2.00 million rows, 18.00 MB (32.56 million rows/s., 293.06 MB/s.)
Code: Setup Clickhouse for a few minutes
Best practices
- Snowflake Best Practices - Slide
- Data Life Cycle Management
- Advanced Schema Design, Best Practices - Video
Internals of Snowflake
Check summary Internals of Snowflake or official document of Snowflake for getting more knowledge base about how Data Warehouse works for enterprise.
Advance
ML
Snowflake Machine Learning SQL for ML in Snowflake - Sample
Important links
Deploying ML model
- To be Updated
Snowflake Machine Learning Deployment Steps to extract and deploy model with docker
Airflow and Snowflake Integration
-
Setup: Copy over the
airflowdirectory (i.e. the Dockerized setup) fromweek_2_data_ingestion: -
Setup S3 Local (MinIO) for storing the raw/landing data, you can get the file of MinIO in this book by searching the MinIO
- Practice File System fs_to_snowflake_dag.py
- Practice S3 s3_to_snowflake_dag.py
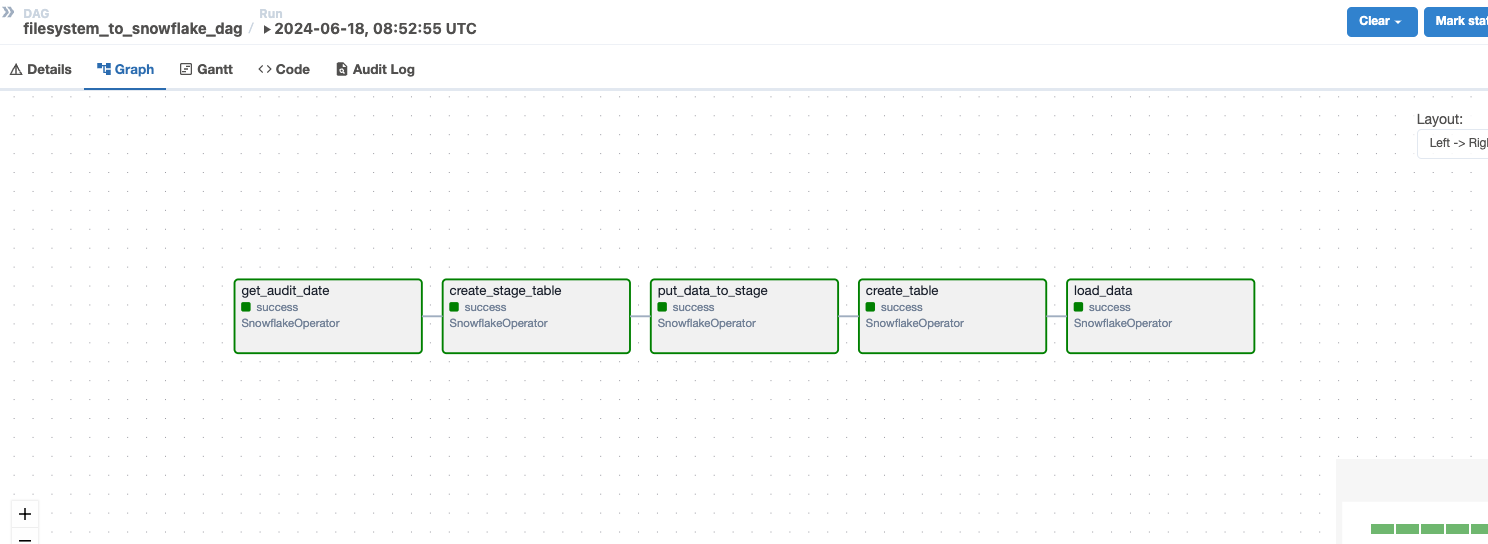
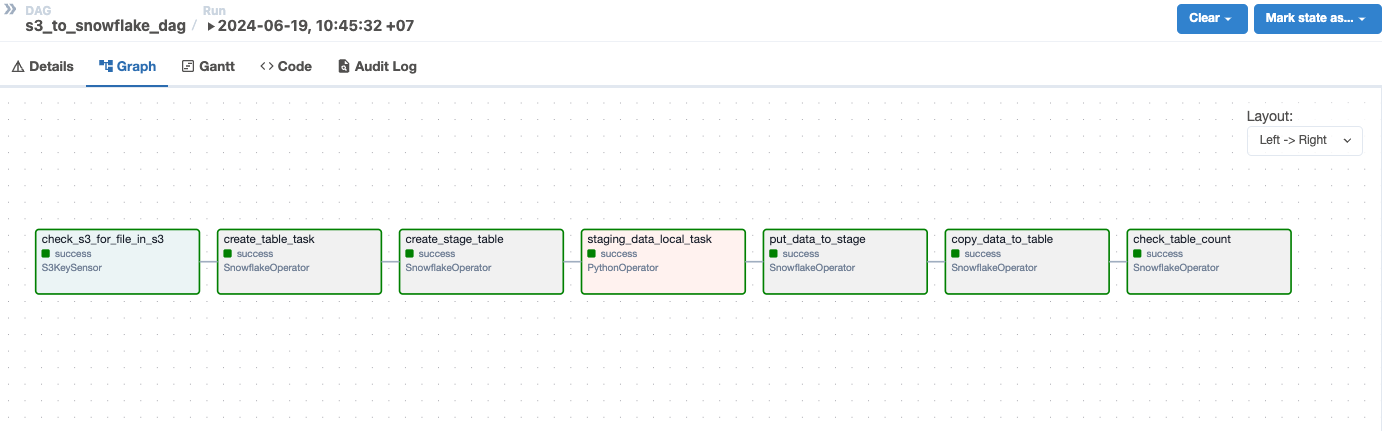
Further Improvement
- Change Snowflake or Postgres to DeltaLake
- Explore Lakehouses
- Deploy to Cloud services
Summary before Jumping
List of DAGs if you are complete Week3
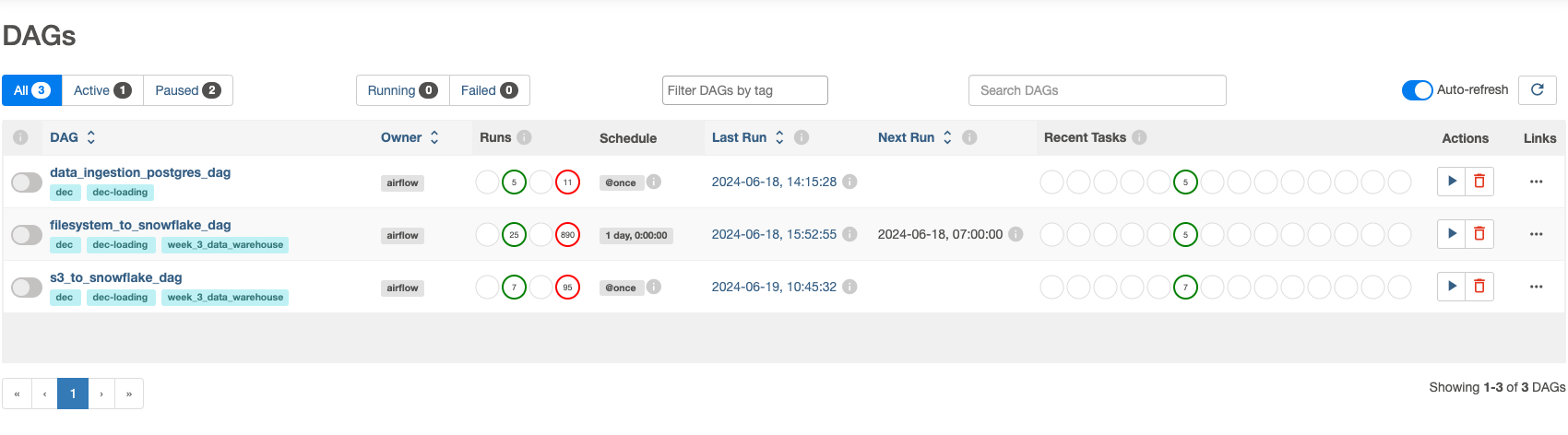
Up coming: Visualize Data, Make a insight, analysis
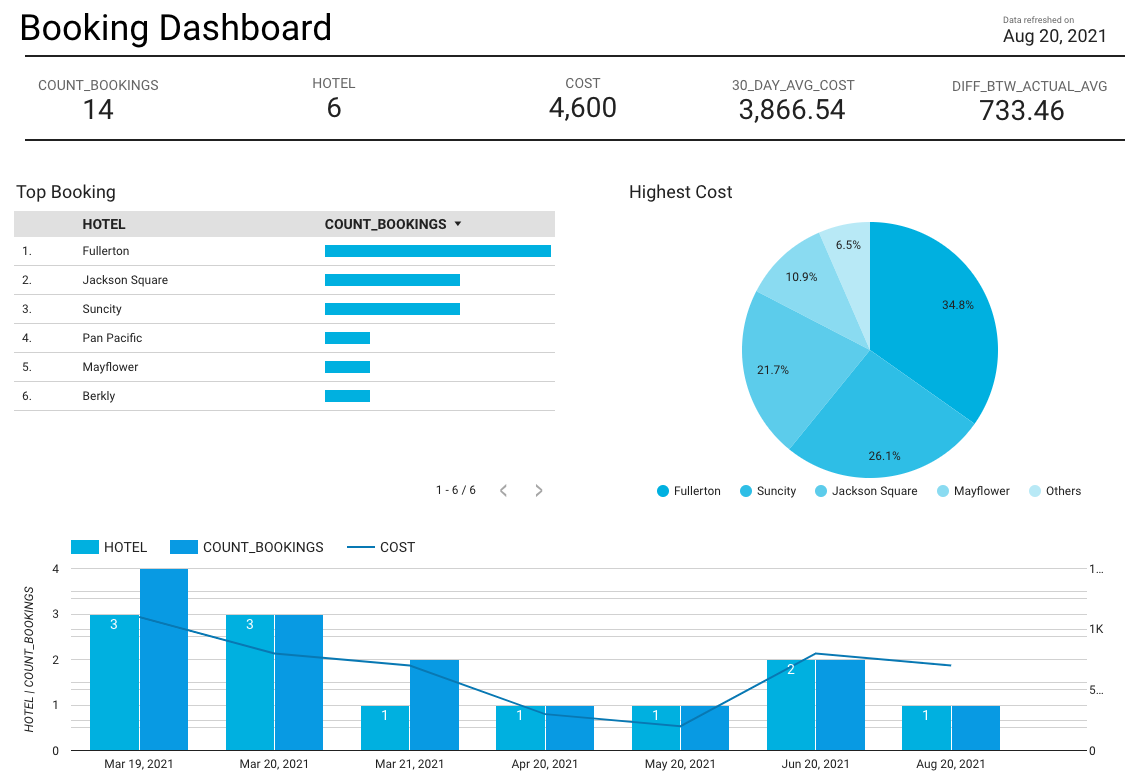
Summary:
- Data Ingestion
- Data Flow Orchestration
- Data Warehousing
- Integration of Ingestion → Warehouse → Automation
What make you better ?
- How to manage data partitions and re-balance data in clustering?
- Determine the impact of CAP theorem in distributed system
- Data Warehouse Architecture, design data loading, vacuum
- Design Atomicity and Idempotent data loading
- Separate Disk shared, compute shared mechanisms
- Lakehouses evolutions, why it changes the data framework