Week 7 - Data Quality
- Introduction to Data Quality
- Key Dimensions of Data Quality
- Data Quality Practices
- Visualizing Data Quality
- Metrics and Rules Definition
- Data Quality with Snowflake
- Data Quality with dbt
- Data Quality with Deequ
- Summary
Introduction to Data Quality
Data quality refers to the condition of a dataset, determined by factors such as accuracy, completeness, consistency, reliability, and relevance. High-quality data is essential for effective decision-making, operational efficiency, and compliance with regulations. Poor data quality can lead to incorrect analyses, misguided decisions, and operational inefficiencies.
Key Dimensions of Data Quality
- Accuracy: Data accurately reflects the real-world entities or events it represents.
- Completeness: All necessary data is present without omissions or missing values.
- Consistency: Data is consistent across different datasets or systems, without conflicting information.
- Timeliness: Data is up-to-date and available when needed, ensuring that decisions are based on the most current information.
- Validity: Data adheres to the defined formats, rules, and constraints, ensuring that it fits within the expected range of values.
- Integrity: Data is correctly structured, and relationships between entities are maintained, ensuring that data dependencies and references are accurate.
Data Quality Practices
Data Validation
Data validation involves checking data against predefined rules or criteria before it is processed or stored. This ensures that only valid data enters the system.
Example: Python Code for Data Validation
import re
def validate_email(email):
# Regex pattern for validating an email
pattern = r"[^@]+@[^@]+\.[^@]+"
return re.match(pattern, email) is not None
def validate_transaction(transaction):
if not transaction.get("transaction_id"):
raise ValueError("Missing transaction_id")
if not transaction.get("amount") or transaction["amount"] <= 0:
raise ValueError("Invalid amount")
if not validate_email(transaction.get("customer_email")):
raise ValueError("Invalid customer_email")
return True
# Sample transaction data
transaction_data = {
"transaction_id": "12345",
"amount": 100,
"customer_email": "customer@example.com"
}
# Validate the transaction data
try:
is_valid = validate_transaction(transaction_data)
print("Transaction is valid:", is_valid)
except ValueError as e:
print("Validation error:", e)
Data Cleaning
Data cleaning involves detecting and correcting errors or inconsistencies in data to improve its quality.
Example: Python Code for Data Cleaning
import pandas as pd
# Sample data with missing and inconsistent values
data = {
"transaction_id": ["12345", "12346", None, "12348"],
"amount": [100, -50, 200, None],
"customer_email": ["customer@example.com", "invalid_email", "another@example.com", None]
}
df = pd.DataFrame(data)
# Drop rows with missing transaction_id
df.dropna(subset=["transaction_id"], inplace=True)
# Replace negative amounts with NaN
df["amount"] = df["amount"].apply(lambda x: x if x >= 0 else None)
# Fill missing values in the 'amount' column with the median
df["amount"].fillna(df["amount"].median(), inplace=True)
# Apply the email validation function to clean the 'customer_email' column
df['customer_email'] = df['customer_email'].apply(lambda x: x if isinstance(x, str) and validate_email(x) else None)
print(df)
Data Quality Monitoring
Continuous monitoring of data quality is crucial to ensure that data remains reliable and accurate over time. This can involve automated checks and alerts when data quality issues arise.
Example: Monitoring Data Completeness
# %% Cell 1
def monitor_completeness(df, column_name):
total_records = len(df)
missing_records = df[column_name].isnull().sum()
completeness_percentage = ((total_records - missing_records) / total_records) * 100
return completeness_percentage
# Create a sample DataFrame
df = pd.DataFrame({
"customer_email": ["a@example.com", None, "c@example.com", "d@example.com", None]
})
completeness = monitor_completeness(df, "customer_email")
print(f"Completeness of 'customer_email': {completeness}%")
Schema Design for Data Quality
Design a schema for storing data quality checks, including quality metrics, failed records, and audit IDs, you can create a set of tables that will help you manage and verify data quality over time. Below is a schema design that includes tables for quality checks, metrics, failed records, and audit logs.
erDiagram
QualityChecks {
INT check_id PK "Primary Key"
VARCHAR check_name
TEXT check_description
TIMESTAMP created_at
TIMESTAMP updated_at
}
QualityMetrics {
INT metric_id PK "Primary Key"
INT check_id FK "Foreign Key"
VARCHAR metric_name
FLOAT metric_value
TIMESTAMP created_at
}
FailedRecords {
INT failed_record_id PK "Primary Key"
INT check_id FK "Foreign Key"
VARCHAR record_id
TEXT failure_reason
TIMESTAMP failed_at
}
AuditLog {
INT audit_id PK "Primary Key"
INT check_id FK "Foreign Key"
TIMESTAMP executed_at
VARCHAR status
TEXT details
}
QualityChecks ||--o| QualityMetrics : has
QualityChecks ||--o| FailedRecords : has
QualityChecks ||--o| AuditLog : has
Figure: Schema Design for Data Quality
This diagram is the least minimum attributes for Quality Audit:
- QualityChecks Table: Stores metadata about each quality check.
- QualityMetrics Table: Stores the results of the quality metrics for each check.
- FailedRecords Table: Logs records that did not pass the quality checks.
- AuditLog Table: Tracks audit records for quality checks, including execution status and details.
This schema design will help you efficiently manage and verify data quality across various checks, storing relevant metrics, failed records, and audit information.
Visualizing Data Quality
Visualizing data quality can help in identifying patterns, trends, and anomalies. A common approach is to create dashboards or charts that track data quality metrics over time.
Data Quality Monitoring Flowchart
flowchart TD
%% Add a transparent text node as a watermark
style Watermark fill:none,stroke:none
Watermark[Created by: LongBui]
A[Start] --> B[Data Ingestion]
B --> C{Validation Rules}
C -->|Valid| D[Store Data]
C -->|Invalid| E[Log Error]
E --> F[Notify Team]
F --> B
D --> G[Monitor Quality Metrics]
G --> H{Issue Detected?}
H -->|Yes| I[Alert Team]
H -->|No| J[Continue Processing]
Figure: Data Quality Workflow
An example dashboard for monitoring data quality might include the following charts:
- Completeness: Percentage of non-null values across key columns.
- Accuracy: Number of records that pass validation rules.
- Consistency: Number of data conflicts across different datasets.
- Timeliness: Data freshness, e.g., how recent the data is.
Implementing robust data quality practices is essential for any data-driven organization. By focusing on key dimensions such as accuracy, completeness, and consistency, and by using tools and techniques for validation, cleaning, and monitoring, we can ensure that the data we rely on is of the highest quality.
Metrics and Rules Definition
Defining clear metrics and rules is essential for evaluating and ensuring data quality. Metrics help quantify the quality of data, while rules provide the criteria against which data is validated.
Example: Metrics and Rules Definition
-
Completeness Metric:
- Metric Definition: Percentage of non-null values in a critical column.
- Rule: A column must have at least 98% non-null values for the data to be considered complete.
- Calculation:
SELECT (COUNT(*) - COUNT(NULLIF(column_name, NULL))) / COUNT(*) * 100 AS completeness_percentage FROM table_name; -
Accuracy Metric:
- Metric Definition: Percentage of data that matches reference or expected values.
- Rule: At least 95% of the records in the dataset must match the expected values or reference data.
- Calculation:
SELECT COUNT(*) AS total_records, SUM(CASE WHEN column_name = expected_value THEN 1 ELSE 0 END) / COUNT(*) * 100 AS accuracy_percentage FROM table_name; -
Timeliness Metric:
- Metric Definition: The average time delay between data collection and availability.
- Rule: Data should be available within 24 hours of its collection.
- Calculation:
SELECT AVG(TIMESTAMPDIFF(HOUR, collection_time, available_time)) AS avg_timeliness FROM table_name;
Practice with:
- Define data quality metrics based on business requirements and data usage.
- Establish thresholds for these metrics that align with acceptable quality standards.
- Regularly monitor these metrics to ensure ongoing data quality.
Data Quality with Snowflake
Snowflake provides robust features to implement data quality checks directly within your data pipelines. By leveraging SQL, Snowflake’s capabilities, and stored procedures, you can automate data quality validation processes.
Example: Implementing Data Quality Checks in Snowflake
-
Create a Data Quality Table:
- Store the results of data quality checks.
CREATE TABLE data_quality_results ( check_name STRING, check_date TIMESTAMP, check_status STRING, failed_records INT, total_records INT, error_message STRING ); -
Completeness Check:
- Ensure no critical columns contain NULL values.
INSERT INTO data_quality_results SELECT 'Completeness Check' AS check_name, CURRENT_TIMESTAMP() AS check_date, CASE WHEN COUNT(*) - COUNT(NULLIF(column_name, NULL)) = COUNT(*) THEN 'PASS' ELSE 'FAIL' END AS check_status, COUNT(NULLIF(column_name, NULL)) AS failed_records, COUNT(*) AS total_records, NULL AS error_message FROM table_name; -
Accuracy Check:
- Verify that data matches reference values.
INSERT INTO data_quality_results SELECT 'Accuracy Check' AS check_name, CURRENT_TIMESTAMP() AS check_date, CASE WHEN COUNT(*) = COUNT(CASE WHEN column_name = expected_value THEN 1 END) THEN 'PASS' ELSE 'FAIL' END AS check_status, COUNT(*) - COUNT(CASE WHEN column_name = expected_value THEN 1 END) AS failed_records, COUNT(*) AS total_records, NULL AS error_message FROM table_name; -
Automate the Data Quality Checks:
- Create a Snowflake stored procedure to automate the execution of these checks.
CREATE OR REPLACE PROCEDURE run_data_quality_checks() RETURNS STRING LANGUAGE SQL AS $$ BEGIN -- Completeness Check INSERT INTO data_quality_results ... -- Accuracy Check INSERT INTO data_quality_results ... RETURN 'Data Quality Checks Completed'; END; $$;
Practice with:
- Implement regular data quality checks within Snowflake using SQL and stored procedures.
- Store the results in a dedicated table for easy tracking and monitoring.
- Automate the execution of these checks to ensure continuous data quality.
Data Quality with dbt
dbt (Data Build Tool) allows you to define and enforce data quality rules within your transformation workflows. By creating tests and using dbt’s built-in capabilities, you can ensure that your transformed data meets the defined quality standards.
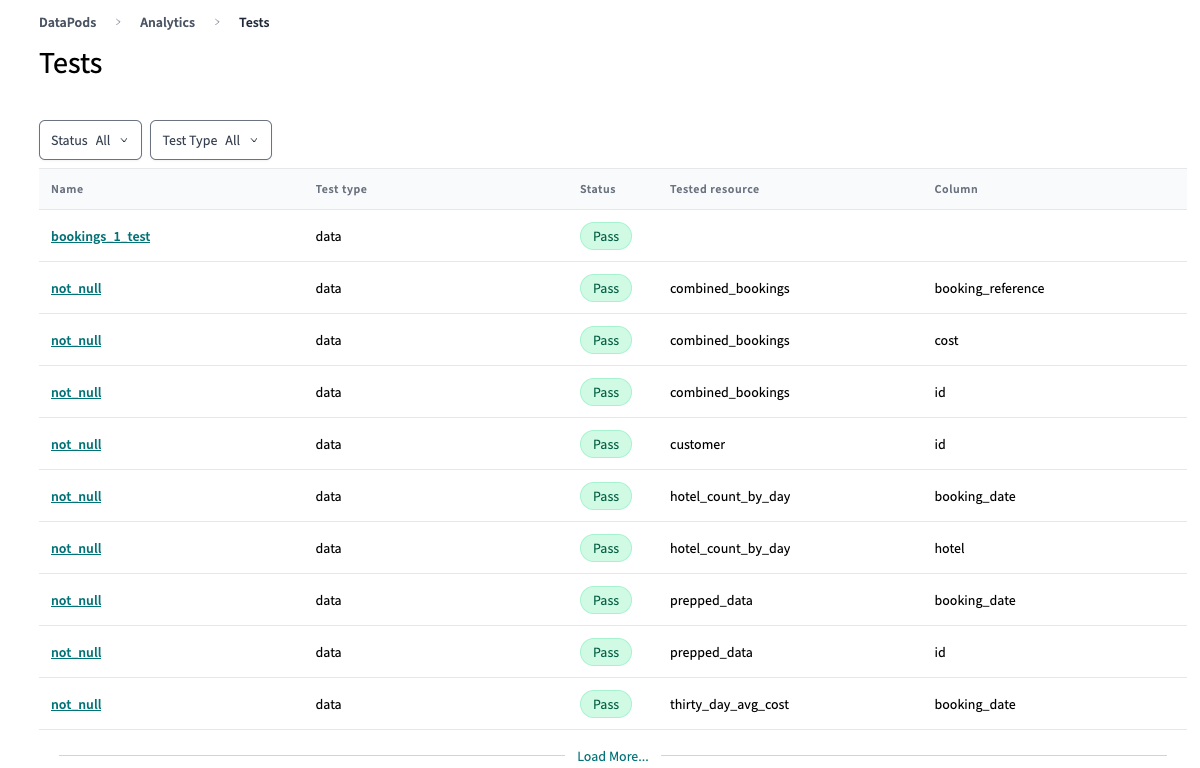
Example: Data Quality Tests with dbt
-
Define a Test for Null Values:
- Create a custom test to check for NULL values in critical columns.
tests: - name: no_nulls columns: - name: column_name tests: - not_null -
Check for Data Consistency:
- Ensure that a column contains only valid predefined values.
tests: - name: valid_values columns: - name: status tests: - accepted_values: values: ['pending', 'completed', 'failed'] -
Run the Tests:
- Execute the dbt tests as part of your transformation pipeline.
dbt test -
Create a Custom Data Quality Model:
- Build a custom model to validate and log data quality checks within your dbt project.
-- models/data_quality_checks.sql WITH null_check AS ( SELECT COUNT(*) AS null_count FROM {{ ref('your_table') }} WHERE column_name IS NULL ) SELECT 'Null Check' AS check_name, CURRENT_TIMESTAMP() AS check_date, CASE WHEN null_count = 0 THEN 'PASS' ELSE 'FAIL' END AS check_status FROM null_check; -
Schedule Regular Tests:
- Use dbt’s scheduling capabilities (e.g., with Airflow) to run tests regularly.
Data Quality with Deequ
Installing deequ into Spark Cluster and init Context
import os
os.environ["SPARK_VERSION"] = "3.3.1"
from pyspark.sql import SparkSession, Row, DataFrame
import json
import pandas as pd
import pydeequ
spark = (SparkSession
.builder
.config("spark.jars.packages", pydeequ.deequ_maven_coord)
.config("spark.jars.excludes", pydeequ.f2j_maven_coord)
.config("spark.driver.memory", "8g")
.config("spark.sql.parquet.int96RebaseModeInRead", "CORRECTED")
.getOrCreate())
- Using Analyzer in Deequ
For Data Profiling
analysisResult = AnalysisRunner(spark) \
.onData(df) \
.addAnalyzer(Size()) \
.addAnalyzer(Completeness("Zone")) \
.addAnalyzer(Distinctness("Zone")) \
.addAnalyzer(Distinctness("service_zone")) \
.addAnalyzer(Completeness("service_zone")) \
.addAnalyzer(Compliance("LocationID", "LocationID >= 0.0")) \
.run()
analysisResult_df = AnalyzerContext.successMetricsAsDataFrame(spark, analysisResult)
analysisResult_df.show()
+-------+------------+------------+------------------+
| entity| instance| name| value|
+-------+------------+------------+------------------+
| Column| Zone|Completeness| 1.0|
| Column|service_zone|Completeness|0.8333333333333334|
| Column|service_zone|Distinctness| 0.6|
| Column| LocationID| Compliance| 1.0|
|Dataset| *| Size| 12.0|
| Column| Zone|Distinctness| 1.0|
+-------+------------+------------+------------------+
- Using Verification
For generating data quality Check
checkResult = VerificationSuite(spark) \
.onData(df) \
.addCheck(
check.hasSize(lambda x: x >= 3000) \
.isContainedIn("service_zone", ["Zone1", "Zone2", "Zone3"]) \
.isUnique("Zone") \
.isComplete("service_zone") \
.isComplete("Zone")).run()

- Visualizing DQ Chart

- Using Auto Suggestion
from pydeequ.suggestions import *
suggestionResult = ConstraintSuggestionRunner(spark) \
.onData(df) \
.addConstraintRule(DEFAULT()) \
.run()
"constraint_suggestions": [
{
"constraint_name": "CompletenessConstraint(Completeness(LocationID,None,None))",
"column_name": "LocationID",
"current_value": "Completeness: 1.0",
"description": "'LocationID' is not null",
"suggesting_rule": "CompleteIfCompleteRule()",
"rule_description": "If a column is complete in the sample, we suggest a NOT NULL constraint",
"code_for_constraint": ".isComplete(\"LocationID\")"
},
{
"constraint_name": "ComplianceConstraint(Compliance('LocationID' has no negative values,LocationID >= 0,None,List(LocationID),None))",
"column_name": "LocationID",
"current_value": "Minimum: 1.0",
"description": "'LocationID' has no negative values",
"suggesting_rule": "NonNegativeNumbersRule()",
"rule_description": "If we see only non-negative numbers in a column, we suggest a corresponding constraint",
"code_for_constraint": ".isNonNegative(\"LocationID\")"
}
]
Summary
These sections provide practical guidance on how to define, implement, and monitor data quality metrics using Snowflake and dbt, ensuring that your data meets the required standards throughout the data lifecycle.